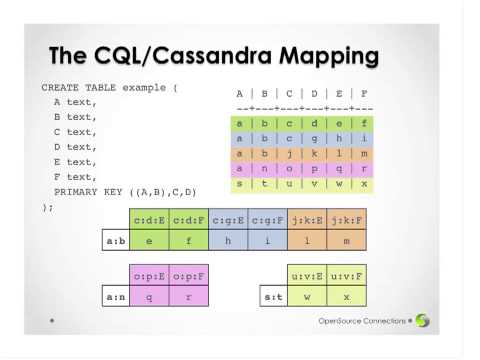
(Recorded at Jfokus 2016. http://www.jfokus.com) Spark Analytics on Cassandra Data Apache Cassandra is a leading open-source distributed database capable of amazing feats of scale, but its data model requires a bit of planning for it to perform well. Of course, the nature of ad-hoc data exploration and analysis requires that we be able to ask questions we hadn?t planned on asking?and get an answer fast. Enter Apache Spark. Spark is a distributed computation framework optimized to work in-memory, and heavily influenced by concepts from functional programming languages. It?s exactly what a Cassandra cluster needs to deliver real-time, ad-hoc querying of operational data at scale. In this talk, we?ll explore Spark and see how it works together with Cassandra to deliver a powerful open-source big data analytic solution. Tim Berglund, DataStax Tim is a teacher, author, and technology leader with DataStax, where he serves as the Director of Training. He can frequently be found at speaking at conferences in the United States and all over the world. He is the co-presenter of various O?Reilly training videos on topics ranging from Git to Mac OS X Productivity Tips to Distributed Systems, and is the author of Gradle Beyond the Basics. He tweets as @tlberglund, blogs very occasionally at http://timberglund.com, and lives in Littleton, CO, USA with the wife of his youth and their youngest child.